導入
なぜ,多くの企業が短期間でヒューマノイドを作れるようになったのか
ここ数年で、ヒューマノイド開発は「一部の研究機関や大企業だけが挑む領域」から、「複数のスタートアップが並走し、短期間で試作機を出す領域」へと様相を変えました。では、なぜ多くの企業が短期間で“動ける身体”を作れるようになったのでしょうか。さらに、なぜ実用化への期待値が急に上がっているのでしょうか。
「AIの進化」と片付けるのは簡単ですが、実際の要因はAIだけではありません。本連載では、ヒューマノイドに興味を持ちはじめた技術者や投資家に向けて、全4回にわたってヒューマノイドを構成する技術的要素がどのように進化してきたかを概観します。なぜ今、ヒューマノイドの実用化への期待値が上がっているのかを技術史観点から紐解く一助になれば幸いです。
初回である本記事では、ヒューマノイドの歩行を中心とした下半身制御の技術を扱います。
本連載は、AGIRobotsがヒューマノイドを実運用可能なシステムとして成立させるうえで、技術要素の成熟度と転換点を整理するために執筆しています。
二足歩行の制御技術はいかにして当たり前になったのか
この問いに対する端的な答えは、「学習ベースの手法が現実的に成立するためのピースが揃った」ことにあります。
ヒューマノイドの特徴といえば、二足での運動ですが、かつては非常に難しい技術であり、「一部の研究機関や大企業だけが長期間かけて挑む領域」でした。例えばホンダは1980年代からヒューマノイドの研究開発を始め、1990年代にP2などを、2000年にASIMOを発表しています。しかし、現在では多くのスタートアップ企業が短期間で二足歩行を行うヒューマノイドを開発し、ときにアクロバットな動きまで見せてくれます。
ASIMO以前からASIMOを代表とした2000年代、そして現代にいたるまでの変化は単なる計算機の性能向上だけでなく、制御技術のパラダイムシフトとハードウェアのコモディティ化に支えられたものです。ハードウェアの話は別の記事に譲り、以下では特に制御技術の変遷を辿ります。
歩行ロボット黎明期 ― 静歩行から動歩行
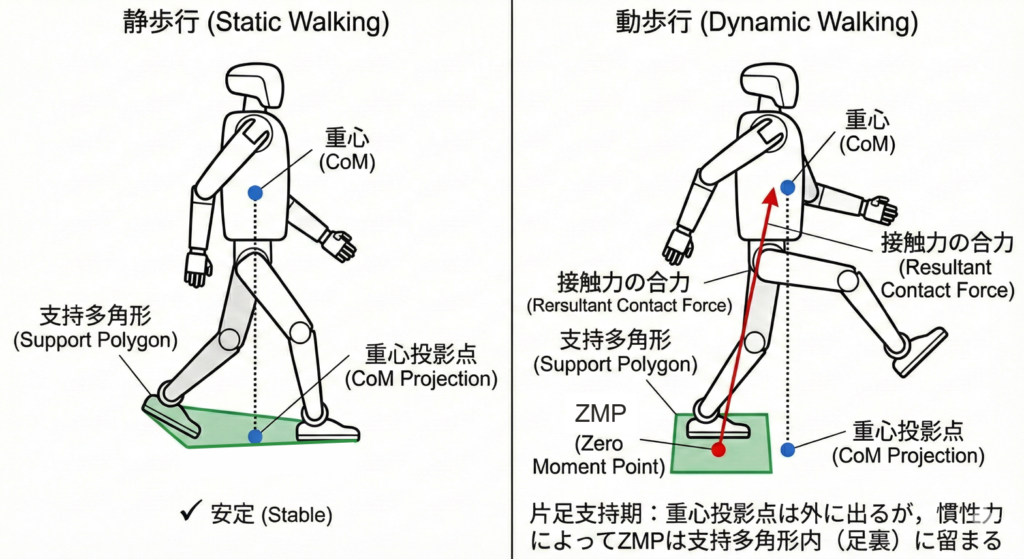
二足歩行ロボットの研究は意外に古く、1960年代後半には既に行われていたようですが、初期の二足歩行は「静歩行」が中心でした。静歩行は重心投影が支持多角形の内側にあるようにゆっくり歩く方法です。この方法は歩行ロボットの安定性の十分条件を満たしますが、過剰な条件となっています。安定性は得やすい一方、速度・効率は犠牲になり、実環境で使えるダイナミクスには届きませんでした。
この壁を越える概念が「動歩行」です。動歩行では、重心の投影点が支持多角形から外れる瞬間があっても、全身の運動量・接触力の制御で転倒を回避します。その理論的な要石となったのがZMP(Zero Moment Point)です。これは1972年にMiomir Vukobratović氏によって提唱された概念1で、支持面上での合力モーメントがゼロになる点を安定性の指標として扱う考え方です。
図で示すと、静歩行ではロボットの重心投影点は常に接地点を囲む支持多角形に入るようにします(支持多角形の描画は視認性のため、実際よりも大きく描いています2)。一方で、動歩行ではロボットの重心投影点ではなく、ZMPが支持多角形に入るようにします。このとき、重心は必ずしも支持多角形の真上にある必要がないため、動歩行ではより大きく足を踏みだす動きができます。
モデルベース手法の成功と限界
線形倒立振子モデルの発明と国内ヒューマノイド研究の隆盛
ZMPの登場以降の初期において、この概念の活用の試みは早稲田大の加藤一郎教授を中心としたグループなどにより行われていましたが、あまり広くその有用性を知られていたわけではありませんでした。
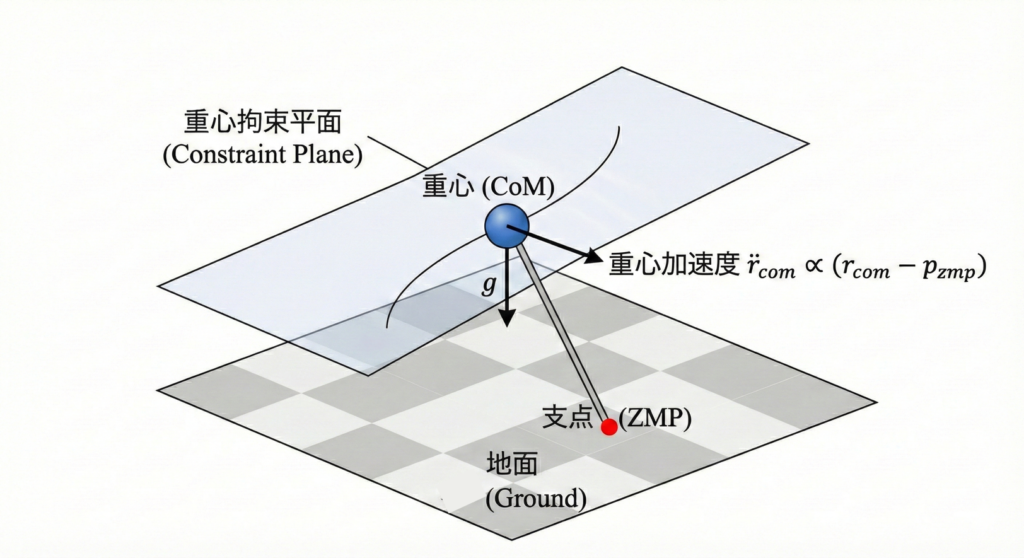
ZMPを規範とする制御が非常に広く知られるようになった転機が、産総研の梶田らが1991年に定式化した線形倒立振子モデル3と、それに基づく制御手法の登場です。線形倒立振子モデルでは、重心運動をZMPを支点とする伸縮可能な倒立振子の運動とみなします。オリジナルの線形倒立振子モデルから多くの派生モデルがありますが、教科書的には重心高さ一定か、下の図のように重心運動がある平面内に拘束されるという制約がつきます。また、角運動量が変化しないという制約もあります。
このモデルを用いて、ZMP制約を満たす重心軌道を計画し、制御する方法が多く提案されています。特に有名なのが、2001年に同じく産総研の梶田らにより発表された線形倒立振子モデルと予見制御を組み合わせた歩容生成で、未来の目標ZMP列を見越して重心を滑らかに追従させる枠組みです。これにより、足先配置の自由度が増し、見通しよく歩行パターンを作れるようになりました。
線形倒立振子モデルは当初の定式化の流れから、最近の論文でも「無質量の脚と重心で近似」と書かれることがありますが、実際には、脚を無質量と仮定しなくとも、同様の形の運動方程式を導くことが可能です4。このモデル化は多自由度のヒューマノイドを少数のパラメータでモデル化することに成功した非常にエレガントな手法であり、ASIMOを含む2000年代の多くのヒューマノイド研究開発が何らかの形で同様の考え方による手法を用いていました。
この時代は日本がヒューマノイド研究開発の牽引役でした。
複雑化の末にモデルベースが直面した限界
こうして線形倒立振子モデルは大きな成功を収めましたが、歩行だけでなく様々な全身運動を行うために拡張が続けられます。例えば角運動量を考慮できるようにしたり、跳躍可能になるようにしたり、階段や壁など、接触点が立体的に分布する場合に対応できるようにしたりなどです。拡張されたモデルはときに難解なものになり、それに基づく制御手法も理解や実装のハードルが高い印象のものが多かったように思います。そのためか、体力のないスタートアップ企業にとってヒューマノイド研究開発への参入の壁はまだ高かったようです。
さらに、全身の力学モデルと接触力を直接扱う手法の成果も、2010年代には目立ち始めました。その代表的な例として、トルク制御と全身運動最適化に基づく動作を示したBoston Dynamicsのロボットが挙げられます。
しかし、いくらモデルを高度にしても「モデル誤差」と「環境の不確かさ」の影響は避けられません。床の摩擦係数、ギアの摩擦、部品の弾性変形、柔らかい床、ケーブルの引っ掛かり等々、現実には事前に正確にモデル化できないものが多くあります。この限界を如実に示したのが2015年に行われたDARPA Robotics Challengeでした。ヒューマノイドによる災害救助をテーマにしたチャレンジでしたが、日本から本選に参加した2チームを含め、多くのチームのロボットが現実の砂地やドアや階段やがれきを前に転倒し、リタイアしました。
あまりに多くの転倒シーンが撮影されたので、ロボットが転倒する場面だけをまとめた動画がIEEE SpectrumによりYouTubeへ投稿されたぐらいです。
学習ベース手法へのパラダイムシフト
強化学習の躍進
DARPA Robotics Challenge以降もしばらくはモデルベースの手法が優勢でした。全身動力学モデルに対する最適化による軌道生成と、モデル予測制御を使い、その場での計算量で現実に対処しようとする手法は2020年前後に最も流行りました。この手法はある程度の成果を上げていますが、多くのスタートアップ企業が短期間でヒューマノイドを開発する現状を生み出したゲームチェンジャーは他にいました。
2010年代後半から、「データから学習する」アプローチをとる手法が少しずつ目立ち始めました。強化学習(Reinforcement Learning)の流行です。これと後に続く模倣学習が現在主流の制御手法となります。
強化学習は、人間が歩き方のルールを作りこむのではなく、仮想空間(シミュレータ)内でロボットに無数の失敗を経験させ、目的を達成するための方策を自ら見つけ出させる手法です。
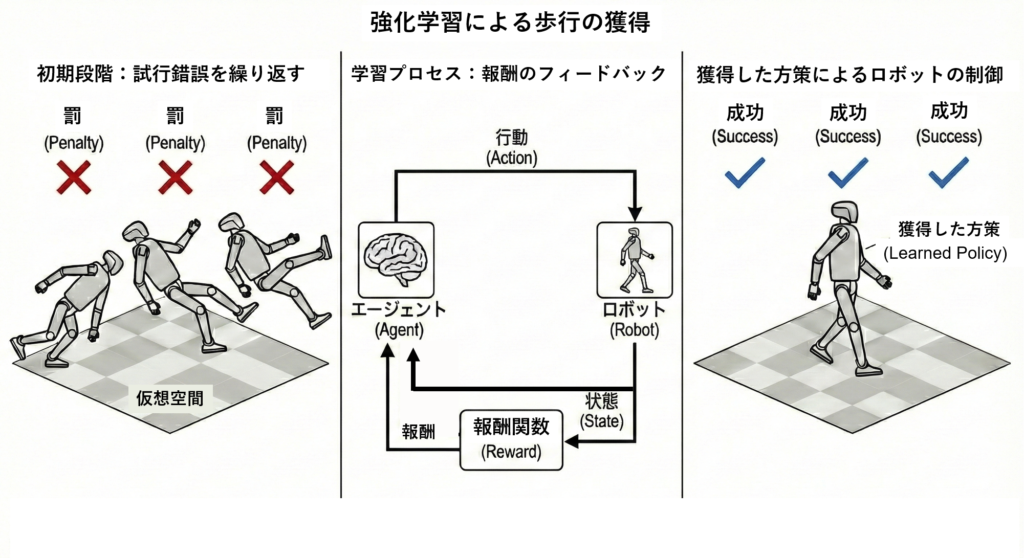
強化学習を用いる手法は以前から研究されていましたが、この手法が現実に対応できるようになったのには以下の要因があります。
- 大規模並列学習
GoogleのBraxや、最近だとNVIDIA Isaac Gym / Isaac LabのようなGPUを活用した並列シミュレーションにより、数千台のロボットを仮想空間で同時に動かし、実時間なら何十年もかかるトレーニングをわずか数時間で完了できるようになりました。
- ドメインランダム化(Domain Randomization)5
シミュレーション内でわざと地面の摩擦を変えたり、重力を変動させたり、機体にランダムな外力を加えたりします。この「ノイズだらけの過酷な環境」で鍛えられたAIモデルは、現実世界の予期せぬ段差や外部からの衝撃に対しても、優れたロバスト性を発揮します。
かつてのモデルベース手法が「モデルが導く正解に現実をいかに追従させるか」を求めていたのに対し、強化学習は「データを基に現実に合わせて動く」能力をロボットに持たせることに成功しました。
AGIRobotsでは、歩行制御を「モデルに現実を合わせる問題」ではなく、「現実のばらつきを前提に方策を獲得する問題」と捉え直すことが、近年の転換点だと考えています。
模倣学習の台頭
強化学習の有効性が示された次のステップとして、今まさに注目を浴びているのが模倣学習(Imitation Learning)です。
強化学習は報酬関数で定められた目的の達成には強い一方、人間のように自然でしなやかな動作をゼロから学習させるには膨大な計算コストと報酬関数の設計センスが必要です。そこで、人間の動作データを収集し、これを用いてロボットに動作をまねさせるように学ばせる手法が取り入れられています。
- テレオペレーション(遠隔操作): 人間がVRデバイスやモーションキャプチャを通じてロボットを操作し、その際の「視覚情報」と「関節の動き」のペアをデータセットとして蓄積します。
- End-to-Endの学習: 蓄積されたデータから、「この状況ではこう動く」という振る舞いをニューラルネットワークが直接学習します。
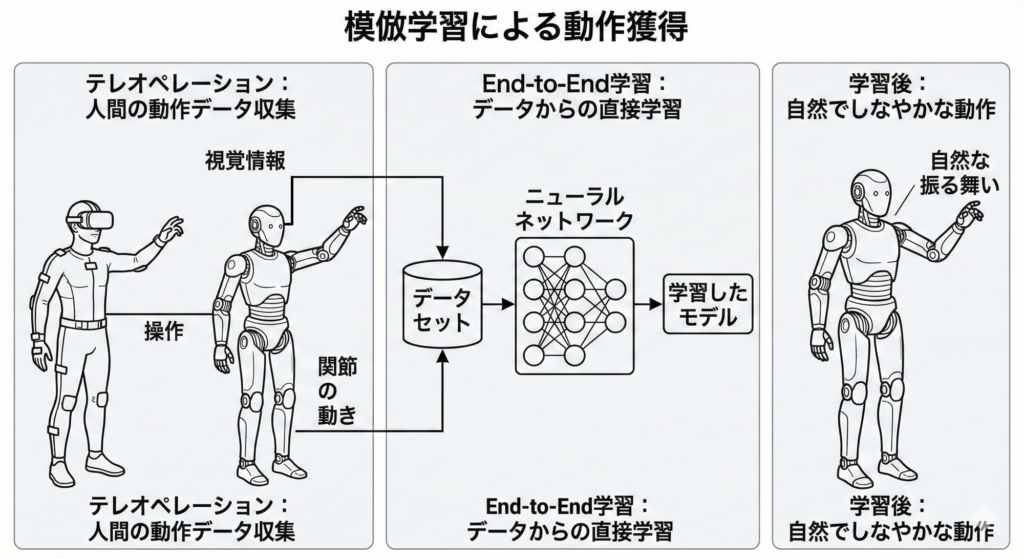
これにより、歩行から作業へのスムーズな移行や、人間と共存しても違和感のない自然な振る舞いが可能になりました。スタートアップ各社がこぞって「データの量と質」を強調しているのは、この模倣学習の精度がそのままロボットの「賢さ」に直結するからです。
この「強化学習による圧倒的な安定性」と「模倣学習による汎用的な動作」の組み合わせ6により、ヒューマノイドの制御技術は以前と比較して簡単に実装でき、しかも優れた性能を示すようになりました。
まとめ
本稿では、ヒューマノイドの歩行をはじめとした下半身制御技術の変遷を辿ることで、なぜ今、ヒューマノイドへの注目が高まっているのかを明らかにしようとしました。
かつてのモデルベース手法では、物理現象を正確に数式化し、膨大なパラメータを職人芸的なチューニングで調整する高度な専門性が必要でした。そのため、ASIMOや産総研のHRPのようなロボットは、限られた体力のある企業や研究機関にしか作れないものでした。
しかし、現在は学習ベース手法の登場により、状況が一変しています。モデルベースだけでは難題だった二足歩行の制御は、今や米国や中国に多くあるスタートアップ企業が短期間で実現するようになりました。
学習ベースの手法は歩行だけではなく、マニピュレーション技術の変遷においても鍵となります。次回はマニピュレーション技術の変遷を取り上げます。
- Miomir Vukobratović and J. Stepanenko (1972). “On the Stability of Anthropomorphic Systems”. Mathematical Biosciences 15: pp.1-37 ↩︎
- 支持多角形を正確に描画しようとすると,平面上の接触点を囲む凸包になります。凸包 – Wikipedia ↩︎
- 梶田,谷:凹凸路面における動的2足歩行の制御について,計測自動制御学会論文集,Vol.27, No.2, pp.177-184, 1991 ↩︎
- この点を強調するためか、重心-ZMPモデルとか、線形倒立振子”モード”と呼ぶ研究者の方もいます。 ↩︎
- Domain Randomizationは学習したポリシーが保守的になるデメリットがあり、近年はその克服手法も提案されていますが、本稿では学習ベース手法への転換点としての意義を重視し、この手法に言及しています。 ↩︎
- 組合せた手法の一例として、A. Tang et al., “HumanMimic: Learning Natural Locomotion and Transitions for Humanoid Robot via Wasserstein Adversarial Imitation,” ↩︎